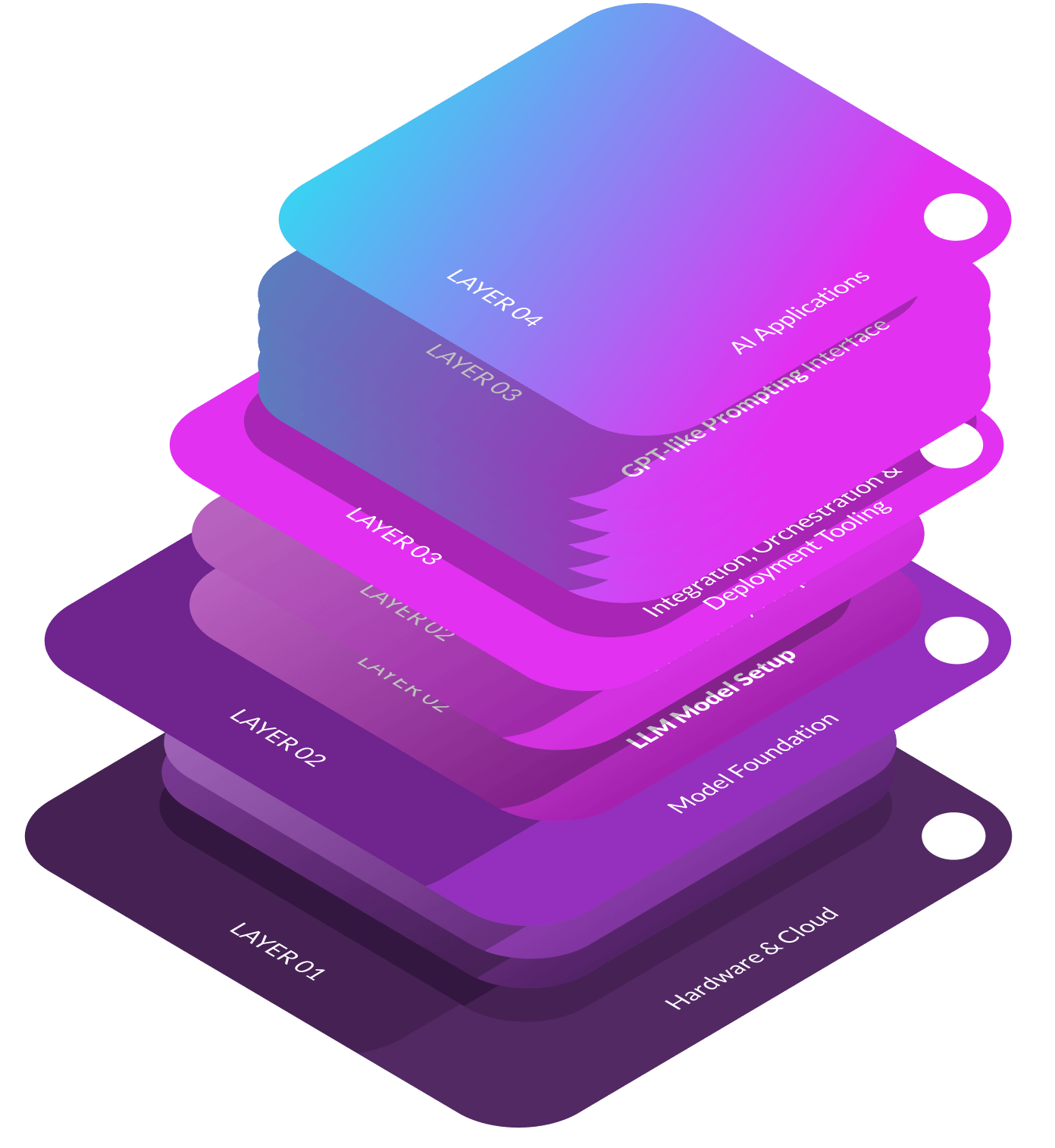
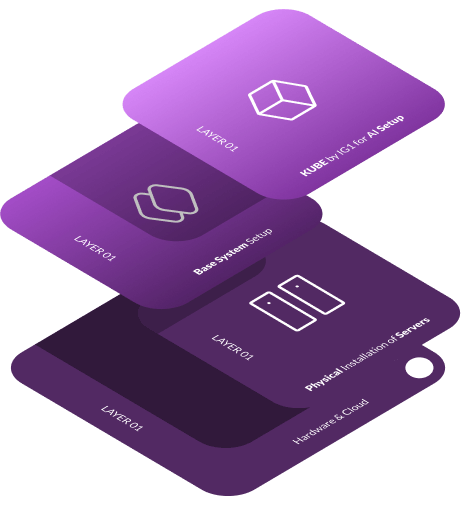
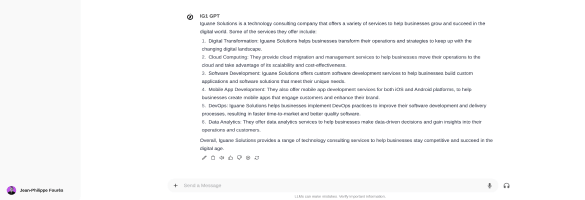
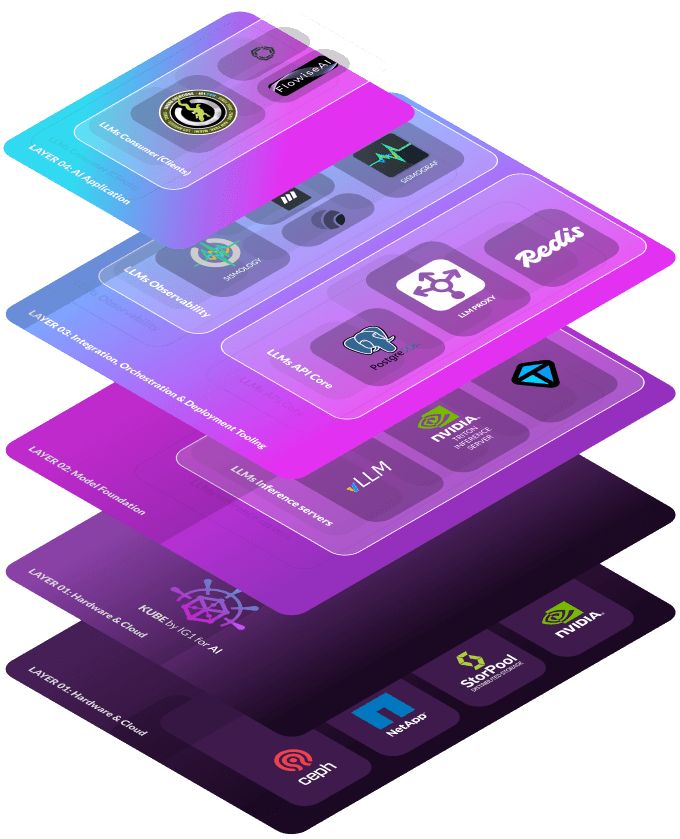
Las herramientas de consumo para LLM salvan la distancia entre el LLM núcleo y las aplicaciones prácticas . Estas herramientas permiten a los desarrolladores integrar modelos generativos en sistemas del mundo real, aumentándolos con información contextual mediante RAG o empleando agentes de herramientas para construir un ejército LLM. Estas herramientas son fundamentales interfaces entre la plataforma de IA y las aplicaciones del usuario final.. Ofrecen capacidades críticas como interfaces de gestión de usuarios y modelos, gestión de claves API, interfaces de documentos para enriquecer el contexto GARun completo Copilot para desarrolladores, que les permite conversar con su código base para mejorar la codificación, y una interfaz de bajo código para crear aplicaciones sin esfuerzo y sin codificación.. Estos servicios plug-and-play facilitan a los desarrolladores y a los miembros del equipo la incorporación de la IA a sus rutinas diarias.