Iguana Solutions es un experto en alojamiento y externalización de infraestructuras informáticas que necesita conocer en tiempo real el estado de todas las infraestructuras bajo su control.
La evolución continua de las distintas capas de software, la llegada de nuevas prácticas de desarrollo como la contenedorización, las nuevas herramientas de desarrollo ágil y las prácticas DevOps generan cada vez más datos que deben recopilarse y centralizarse para actuar y reaccionar cada vez más rápido. La implementación de la observabilidad es la solución adoptada por nuestros equipos técnicos para llevar a cabo sus misiones con éxito.
Observabilidad: Definición
La observabilidad es la capacidad de observar el comportamiento de un sistema. Para lograrlo, el sistema debe estar instrumentado en los 3 pilares siguientes:
Métricas: Mide el estado de la plataforma y sus servicios. Más concretamente, las métricas son elementos cuantificados que se miden en un momento dado y con una frecuencia regular, lo que permite trazar curvas de evolución a lo largo del tiempo.
Logs: archivos de texto que contienen toda la información sobre el estado de la aplicación: nuevas conexiones, mensajes de error, mensajes para desarrolladores. Los registros de aplicaciones son útiles para investigar las causas raíz de las incidencias, como complemento de las métricas.
Rastreo: Seguimiento horizontal de una petición a través de varias aplicaciones. Útil para comprender el comportamiento de una aplicación y mejorarla.
Otro término utilizado a menudo en este contexto es "monitorización". La monitorización es la acción de seguir el comportamiento de un sistema.
Debe tenerse en cuenta que la configuración de la recopilación de trazas de aplicaciones es intrusiva y puede tener un impacto significativo en el rendimiento.
En pocas palabras:
- Observabilidad: el concepto de observar el comportamiento de la aplicación a través de 3 elementos: métricas, registros y trazas de la aplicación.
- Supervisión: acción de vigilar y, en su caso, alertar sobre el comportamiento anormal de una aplicación o sistema.
Observabilidad: Aplicación
En 2018, nuestro sistema de supervisión histórico basado en Naemon y Graphite empezaba a mostrar algunas limitaciones y, sobre todo, ya no cubría todas nuestras necesidades para garantizar un nivel de servicio óptimo para nosotros y nuestros clientes. La web stack se estaba quedando anticuada, y cualquier modificación para incluir nuevas plataformas resultaba compleja. Además, nuestro sistema sólo monitorizaba las métricas "de sistema" de los equipos.
Por estas razones, decidimos implantar una nueva solución de metrología con las siguientes especificaciones:
- Recopilar métricas de hardware
- Recopilar métricas del sistema (vista del sistema de recursos: CPU, RAM, almacenamiento, red)
- Recopilar las métricas de servicio requeridas por las aplicaciones (nginx, apache, php, mysql, mongoDB, elasticsearch, Docker, Kubernetes, ...)
- Recopilar registros del sistema
- Recopilar registros de servicio
- Controlar la cantidad y/o cardinalidad de cada métrica
- Sistema multiusuario (aislamiento del cliente)
- Interfaz de visualización para nosotros y nuestros clientes
- Retención de métricas muy larga, ilimitada si es posible
La sección "Rastreo de aplicaciones" no forma parte del pliego de condiciones, ya que el rastreo de aplicaciones recoge información directamente del código fuente de las aplicaciones que alojamos.
Como un servicio PaaS (Platform as a Service), a través de la externalización proporcionamos plataformas específicas para las necesidades de nuestros clientes. Una plataforma agrupa la capa de infraestructura, la parte de sistema (SO + servicios de aplicación) y toda la observabilidad del paquete Infraestructura + Sistema. La parte de software (código de aplicación) sigue siendo responsabilidad de nuestros clientes. No obstante, previa solicitud, en el marco de una investigación o con fines de optimización, podemos ofrecer el despliegue de una herramienta de recogida de trazas de aplicaciones para optimizar el funcionamiento de toda la plataforma.
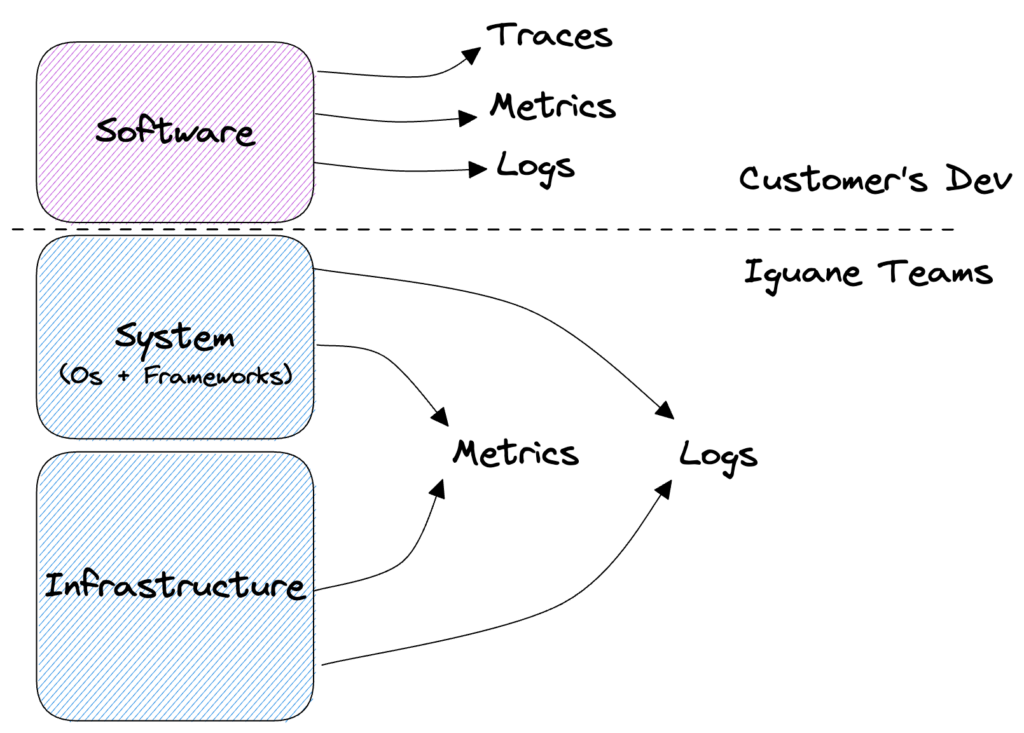
Figura: Representación de las distintas capas de una aplicación informática con sus respectivos elementos de observabilidad.
Basándonos en las especificaciones anteriores, teníamos 2 opciones:
- Utilice una herramienta de observabilidad del mercado como Datadog, Dynatrace o Splunk, por ejemplo.
- Apoyarnos en un conjunto de herramientas Open Source como Prometheus, VictoriaMetrics, InfluxDB, Grafana y desarrollar las partes que nos faltan.
Tras un rápido estudio, llegamos a la siguiente tabla comparativa:
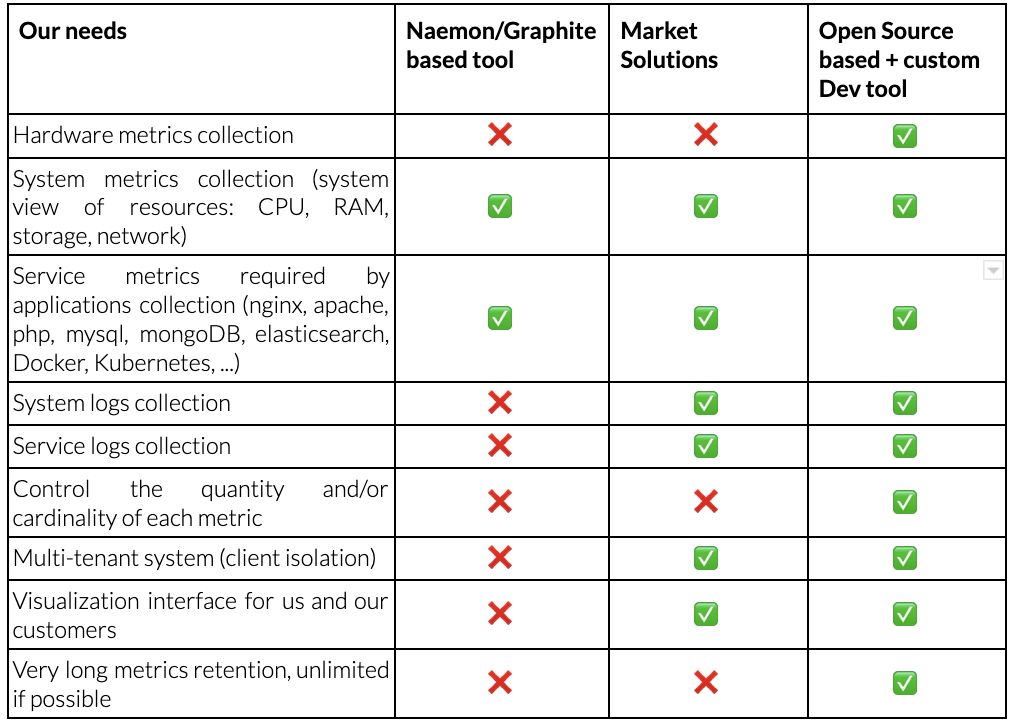
La columna "Código abierto + herramienta basada en desarrollo" gana la votación como la opción más maleable. Los desarrollos propios nos permiten añadir requisitos que no están presentes en las soluciones de código abierto:
- Vincula el software seleccionado,
- Intercambios seguros (configuración TLS entre cada componente)
- Aislar a los clientes.
- Disponer de nuestro propio agente para recopilar métricas y registros
Esta combinación de soluciones de código abierto y desarrollos propios es la única que realmente satisface nuestras necesidades en términos de modularidad, integración de métricas de hardware, largo tiempo de retención y menor coste total que una solución SaaS en el mercado.
Esta opción también nos da un control total sobre la cadena de procesamiento de la información, desde la generación hasta el procesamiento y el almacenamiento.
Este proyecto interno se llama Sismología.
Arquitectura y funcionamiento de la sismología
La arquitectura y la lógica de funcionamiento de Sismology siguen siendo muy sencillas:
- Agente de recogida de métricas y registros en todos los equipos
- 2 dispositivos (se requiere redundancia) por organización del cliente: servidores con Prometheus (recopilación de métricas) y Fluentd (recopilación de registros)
- Victoria Metrics cluster (centralización de todas las métricas con identificación del cliente para su aislamiento) y Loki (centralización de logs)
- Dentro de las métricas de Victoria cluster hemos desarrollado 2 servicios para apoyar la gestión automática y segura del aislamiento de clientes:
- Sismology Ingester: que inserta métricas para un cliente determinado basándose en los ID de dispositivo Sismology del cliente.
- Seleccionador de sismología: hace lo mismo para seleccionar las métricas adecuadas para la interfaz de visualización.
- Visualización mediante cuadros de mando Grafana con gestión por organización de clientes
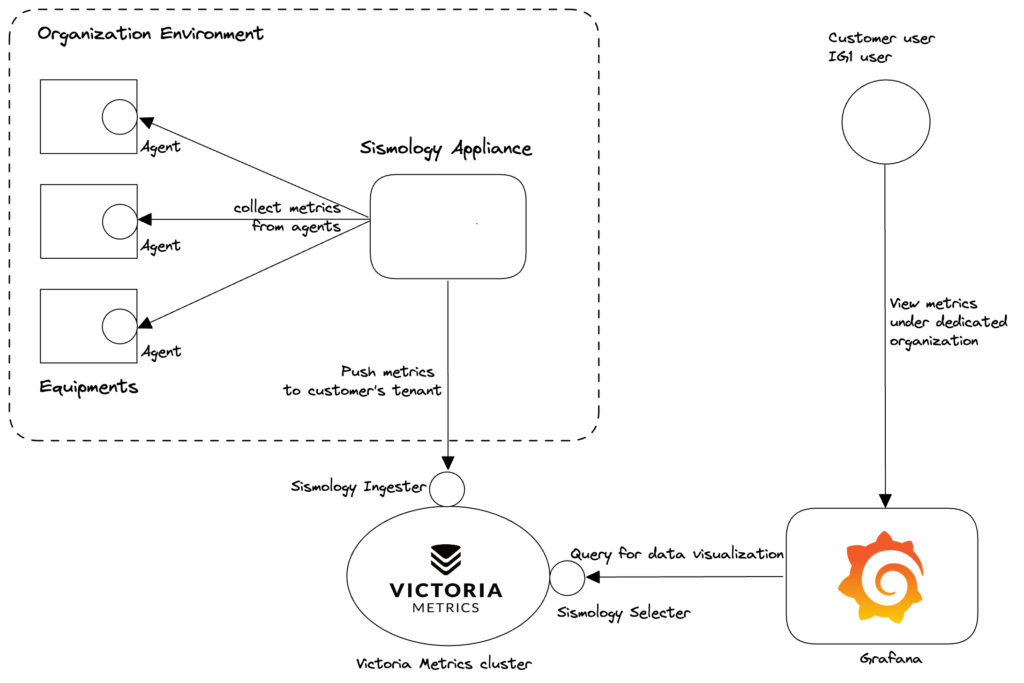
Figura: Diagrama de flujo de métricas desde los equipos hasta la visualización pasando por la recogida
Para la recogida de métricas, hemos desarrollado un conjunto de plugins adaptados a cada tipo de servicio medido: sistema, hardware, mysql, php, apache, etc. Cada agente activa los plugins necesarios únicamente en función de los servicios configurados en el dispositivo.
Para centralizar las métricas, inicialmente optamos por utilizar InfluxDB como herramienta de agregación de puntos métricos. Sin embargo, pronto nos enfrentamos a problemas de rendimiento que se deterioraron con la incorporación de nuevos equipos.
Tras un poco de investigación y algunos benchmarks más, elegimos VictoriaMetrics por su agregación de puntos, su compatibilidad con Grafana y la posibilidad de desplegarlo en "Alta Disponibilidad" cluster en su versión OpenSource. Además, VictoriaMetrics cuenta con excelentes capacidades de deduplicación y compresión de datos que mejoran con el tiempo: cuantos más datos hay, mejor es la compresión sin degradar el rendimiento. Además, VictoriaMetrics permite una gestión sencilla de las diferentes organizaciones y, por tanto, un aislamiento limpio de los datos. Por último, VictoriaMetrics se integra perfectamente con Grafana, por lo que rediseñar nuestros cuadros de mando de visualización no fue una tarea compleja.
Más detalles técnicos sobre nuestro uso de VictoriaMetrics: https://medium.com/iguanesolutions/sismology-iguana-solutions-monitoring-system-f46e4170447f
Para la sección de Logs, hemos desarrollado nuestra herramienta de recopilación y centralización de logs en torno a Fluentd (recopilación) y Loki (centralización). Loki es una herramienta desarrollada por Grafana Labs y se integra perfectamente con Grafana para facilitar la visualización y navegación de logs.
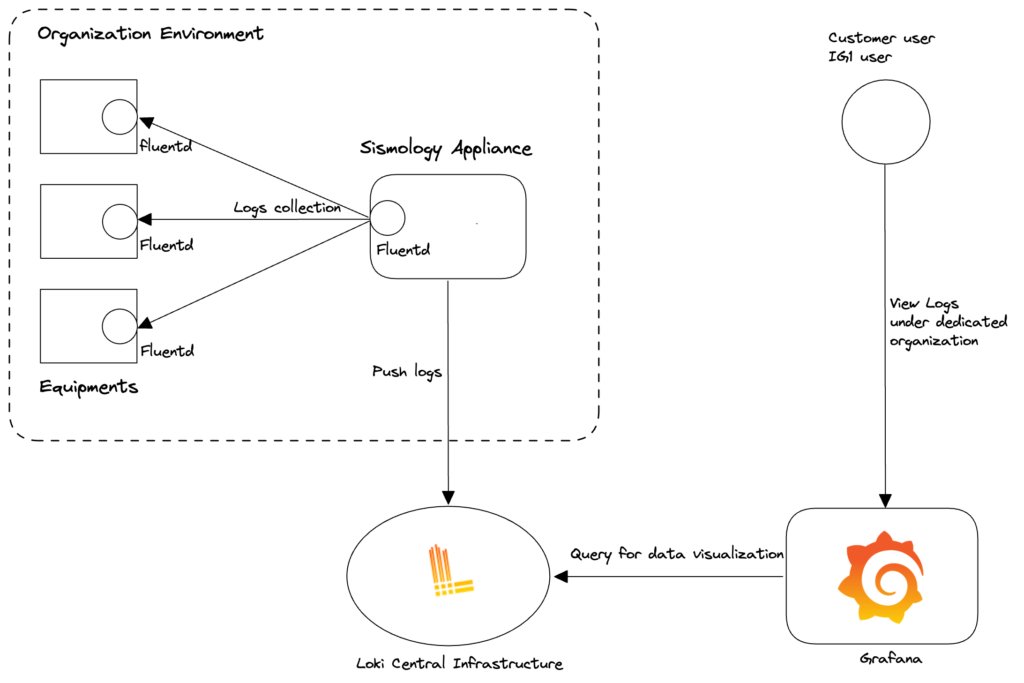
Figura: Diagrama de flujo de registros entre equipos, recogida, almacenamiento y visualización
Este último punto es muy importante, ya que facilita la investigación en caso de que se produzca un evento anómalo. En el mismo Grafana Dashboard, puedes ver las métricas y los registros de un sistema durante un periodo determinado.
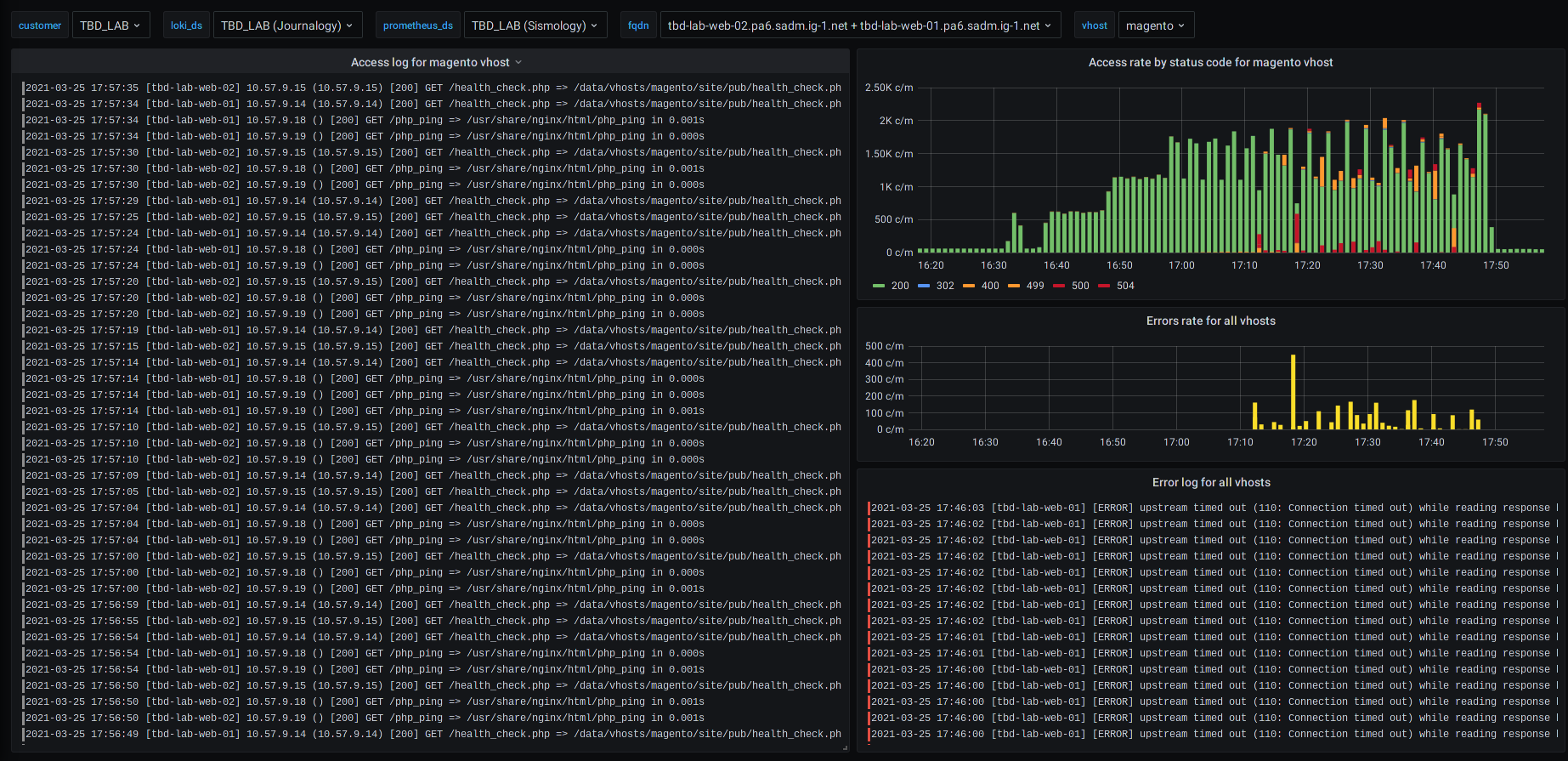
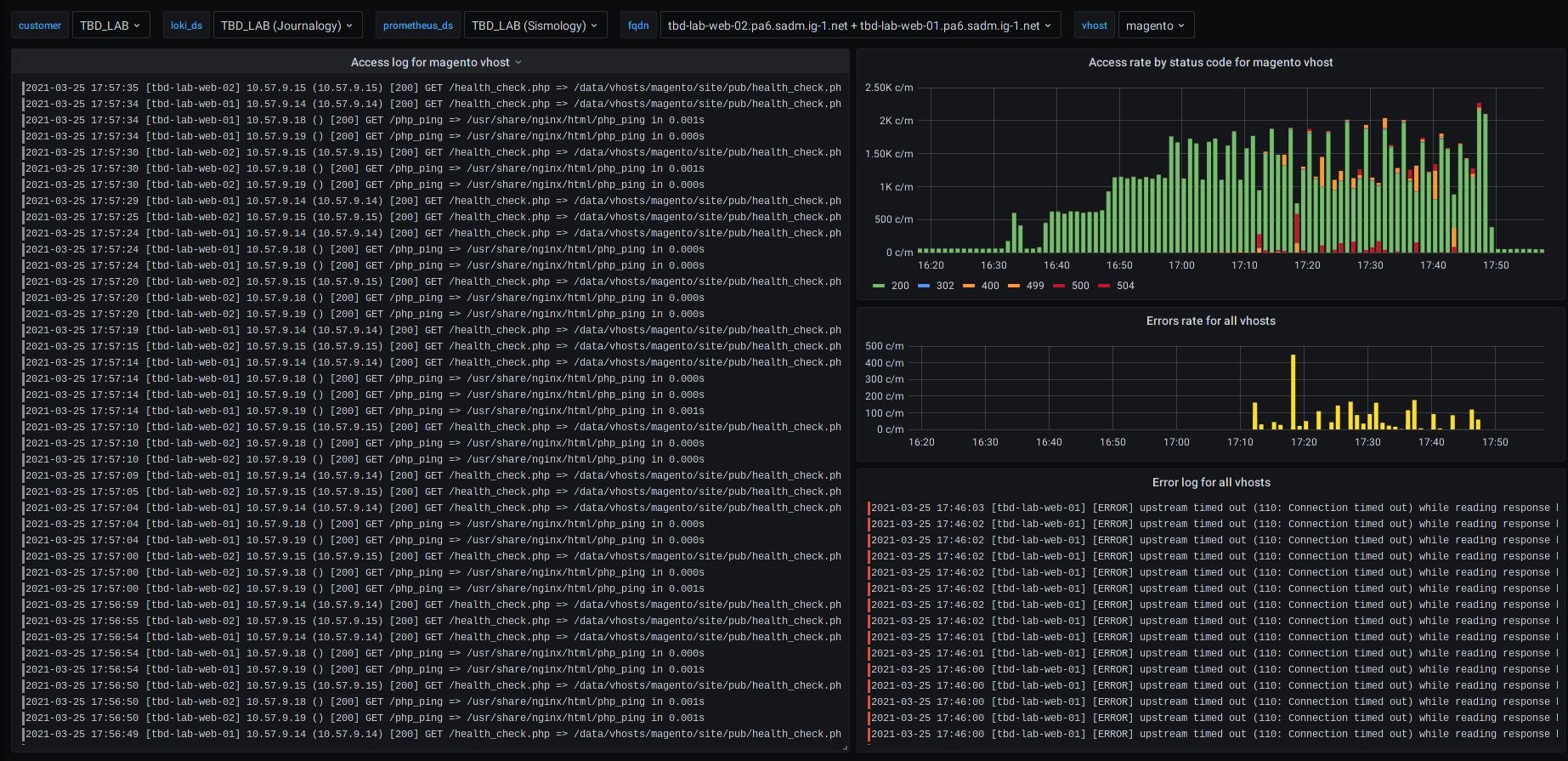 Figura: Ejemplos de diferentes cuadros de mando de servicios para un sitio de comercio electrónico (basado en Magento)
Figura: Ejemplos de diferentes cuadros de mando de servicios para un sitio de comercio electrónico (basado en Magento)
Por ejemplo, en caso de error HTTP en un servidor web, puede ver el progreso del error y los registros correspondientes en la misma pantalla.
Nuestros equipos de asistencia y expertos ahorran un tiempo precioso en caso de incidente o suceso anómalo.
Nuestras ventajas
Disponemos de una solución modular y segura para recopilar y centralizar métricas y registros de todas las plataformas. Gracias a estos datos, pudimos desarrollar una herramienta de supervisión eficaz.
Esta herramienta de gestión de alertas, directamente integrada con Sismology, nos permite activar el soporte o la atención telefónica en cualquier momento, según los criterios definidos por nuestros expertos en DevOps. Nuestro gestor de alertas está conectado a PagerDuty (activación del soporte), así como a Slack, donde recibimos notificaciones en tiempo real de todas las alertas en todas las plataformas. Esto significa que podemos reaccionar inmediatamente, sea cual sea la naturaleza de la alerta, y resolver cualquier anomalía lo antes posible.
La implantación de la detección preventiva de incidentes y la incorporación de la detección de problemas de hardware por parte de Sismología han reducido considerablemente su impacto en los sistemas de los clientes, lo que a su vez ha mejorado nuestros acuerdos de nivel de servicio.
Conclusión
La observabilidad es un componente crítico de cualquier solución de supervisión de plataformas informáticas. Para nosotros, se encuentra en el corazón mismo de nuestro negocio, y requiere la implantación de una solución fiable, eficiente y adaptada a nuestras necesidades.
Por tanto, nuestra herramienta de metrología se centra en 2 de los 3 pilares de la observabilidad: las métricas y los registros.
Con Sismology, tenemos una herramienta sencilla, eficaz y fácil de mantener, con sólo lo esencial para mantenerla lo más simple posible. Todos nuestros equipos técnicos contribuyen a la evolución de la herramienta añadiendo regularmente nuevos plugins para soportar un nuevo marco o para evolucionar la colección de un servicio existente. Tras más de 4 años de uso, hemos probado un gran número de casos de uso, y ofrecemos a nuestros clientes cuadros de mando que les permiten supervisar fácilmente el comportamiento de sus plataformas.
Para recordar:
- Observabilidad: 3 ejes para observar el comportamiento de las aplicaciones: métricas, registros, trazas de aplicaciones
- Supervisión: acción de controlar el comportamiento de la plataforma basándose en la observabilidad.
- La aplicación requiere el despliegue de herramientas:
- o bien herramientas "llave en mano" con una amplia gama de integraciones : Datadog, Dynatrace, Splunk...
- o herramientas Open Source probadas, con trabajo de desarrollo necesario para adaptarlas: Prometheus, VictoriaMetrics, Fluentd, Grafana...
- Sismología: La solución de metrología de Iguane Solutions, que se centra en las métricas y registros esenciales para las plataformas del cliente que se van a supervisar.
